ZFS
Общая информация
В разделе Хранилища - ZFS основного меню содержится информация обо всех хранилищах ZFS, сконфигурированных в системе. ZFS-хранилища являются локальными, но возможности данных хранилищ значительно шире, чем у локальных файловых хранилищ. Создавая хранилище ZFS, необходимо подготовить сервер к созданию на нем пула данных типа zfs.
Создание
Для создания ZFS-хранилища необходимо в разделе Хранилища - ZFS основного меню нажать кнопку Добавить ZFS. В открывшемся окне необходимо выбрать и заполнить следующие поля:
-
сервер размещения ZFS (выбор из раскрывающегося списка);
-
тип пула (выбор из раскрывающегося списка). В типе пула необходимо выбрать режим RAID, который будет применяться к входящим в состав ZFS-хранилища дискам. Доступны следующие режимы:
-
stripe;
-
mirror;
-
raidz1;
-
raidz2.
Режимы raidz1 и raidz2 соответствуют RAID5 и RAID6 соответственно;
-
-
локальные устройства (выбор из раскрывающегося списка);
-
LUN-устройства (выбор из раскрывающегося списка);
-
название и описание пула.
После заполнения полей необходимо подтвердить операцию, нажав кнопку ОК.
Примечание
В списке доступных блочных устройств показываются только устройства без разметки (разделов). Чтобы очистить требуемое устройство от ранее созданной разметки, необходимо воспользоваться командой CLI wipefs, после этого устройство появится в списке. В случае устройств LUN, возможно, потребуется отключить и заново подключить устройство.
Возможна ситуация, когда устройство отсутствует и в списке доступных для создания ZFS пулов, и в списке доступных для очистки. В этом случае вероятнее всего оно сохранилось в кэше ZFS, а сам пул уже не существует или не активен. Чтобы выяснить это, необходимо воспользоваться командой zdb. Если в полях "path" вывода команды есть нужные нам устройства, а ZFS пул, указанный в поле "name" вывода и к которому относятся данные устройства, отсутствует на узле, то мы можем убрать этот пул из кэша командой zpool destroy <pool_name>. После этого нужные нам устройства можно будет очистить командой CLI wipefs и использовать далее.
Операции
Управление работой ZFS-хранилища происходит в окне состояния, которое открывается при нажатии на название хранилища. Логика управления ZFS соответствует управлению работой RAID-контроллера. В окне состояния ZFS-хранилища доступны следующие операции:
-
обновление информации по кнопке
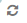
-
расширение (добавление блочных устройств верхнего уровня). Операция Расширить доступна для ZFS с типом пула stripe. Операция «приклеивает» дополнительные устройства к имеющемуся хранилищу. При нажатии кнопки Расширить в открывшемся окне необходимо выбрать из раскрывающегося списка НЖМД сервера (local_devices) или подключенные к серверу сетевые блочные устройства (lun_devices), после чего подтвердить операцию, нажав кнопку ОК;
Примечание
Добавлять можно только по одному устройству. Один из списков или оба могут быть пустыми, если нет доступных устройств.
-
монтирование блочного устройства. Операция Примонтировать доступна для ZFS с типами пула stripe и mirror, в составе которого только один диск. Операция преобразует хранилище в тип mirror. При нажатии кнопки Примонтировать в открывшемся окне необходимо выбрать из раскрывающегося списка тип блочного устройства и присоединяемое устройство (НЖМД или LUN), после чего подтвердить операцию, нажав кнопку ОК;
-
добавление устройства горячей замены. Операция Добавить устройство горячей замены позволяет отметить неиспользуемое системой устройство как hot-swap для данного хранилища. При нажатии кнопки Добавить устройство горячей замены в открывшемся окне необходимо выбрать из раскрывающегося списка НЖМД сервера (local_devices) или подключенные к серверу сетевые блочные устройства (lun_devices), после чего подтвердить операцию, нажав кнопку ОК;
-
добавление устройства кэширования. Операция Добавить устройства кэширования позволяет добавить кэш для ZFS RAID-массива. При нажатии кнопки Добавить устройство кэширования в открывшемся окне необходимо выбрать из раскрывающегося списка НЖМД сервера (local_devices) или подключенные к серверу сетевые блочные устройства (lun_devices), после чего подтвердить операцию, нажав кнопку ОК;
-
сброс ошибок в пуле. При нажатии кнопки Сброс ошибок в открывшемся окне необходимо подтвердить операцию, нажав кнопку Да;
-
проверка целостности данных (scrub). При нажатии кнопки Проверка целостности (scrub) в открывшемся окне необходимо подтвердить операцию, нажав на кнопку Да;
-
получение расширенных сведений;
-
удаление пула. Операция Удалить позволяет расформировать ZFS-хранилище. При нажатии кнопки Удалить в открывшемся окне необходимо подтвердить операцию, нажав кнопку Удалить.
В окне состояния хранилища содержатся сведения, разделенные на следующие группы:
-
Информация.
-
Пулы данных.
-
События.
-
Задачи.
-
Теги.
В окне Хранилища – ZFS – <имя ZFS-пула> – Информация отображаются следующие сведения о ZFS-хранилище:
-
название;
-
описание (редактируемый параметр);
-
сервер;
-
состояние;
-
общий размер;
-
свободное пространство;
-
дата и время создания;
-
дата и время изменения;
-
локальные устройства (раскрывающийся список). Каждое устройство содержит следующие сведения:
-
размер;
-
состояние;
-
кэширование;
-
устройство горячей замены.
Для каждого устройства доступны операции:
-
включение (выключение). При нажатии кнопки Вкл/выкл устройство открывается окно, в котором необходимо подтвердить операцию, нажав кнопку Да;
-
замена устройства. При нажатии кнопки Замена устройства открывается окно, в котором необходимо выбрать local_device, после чего подтвердить операцию, нажав кнопку ОК;
-
демонтирование устройства. При нажатии кнопки Демонтирование устройства открывается окно, в котором необходимо подтвердить операцию, нажав кнопку Да. Удаление диска из состава ZFS возможно только для хранилища, в составе которого два или более дисков. Если в составе ZFS с типом mirror останется только один диск, то он преобразуется в тип stripe;
-
-
устройства LUN (раскрывающийся список);
-
дополнительные характеристики (раскрывающийся список):
- включение или отключение автозамены; - точка монтирования; - сдвиг (ashift).
Пулы данных
В окне Хранилища – ZFS – <имя ZFS-пула> – Пулы данных отображаются созданные в хранилище пулы данных в табличном виде, включая для каждого из них его название, тип, количество серверов, виртуальных дисков, образов и файлов, использованный объем и статус. При нажатии на название пула открывается окно состояния, в котором доступны следующие операции:
-
обновление информации по кнопке
-
извлечение пула. При нажатии кнопки Извлечь в открывшемся окне необходимо подтвердить операцию, нажав кнопку ОК;
-
очистка пула. При нажатии кнопки Очистить в открывшемся окне необходимо определить необходимость принудительной очистки, после чего подтвердить операцию, нажав кнопку ОК;
-
удаление диска (если допускается). При нажатии кнопки Удалить необходимо подтвердить операцию, нажав на кнопку Удалить.
Информация
В окне Хранилища – ZFS – <имя ZFS-пула> – Пулы данных – <имя пула данных> – Информация содержатся следующие сведения о пуле данных:
Пример
ARC-кэш
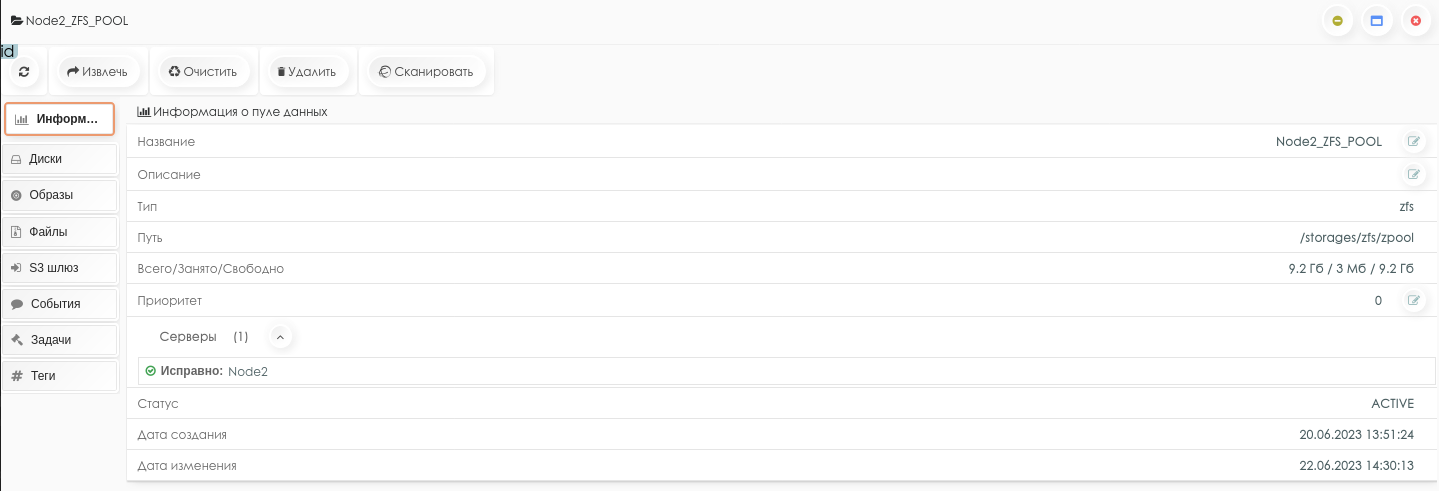
При создании ZFS-пулов необходимо учитывать адаптивное использование памяти сервера под ARC-кэш.
Пример использования памяти сервера подсистемой ZFS до и после сброса кэша (видно изменение ARC size (current)):
Одним из основных моментов, о котором необходимо помнить при использовании ZFS на гипервизоре, является тот факт, что balloon ВМ, использующийся для оптимизации выделения и возвращения неиспользуемой памяти, некорректно работает вместе с динамическим ARC. Поэтому хорошим тоном будет выделение фиксированной памяти для ВМ: balloon=0 и указания максимального размера ARC, таким образом, чтобы суммарная утилизация памяти для машин и кэша была меньше общего количества RAM на 2 Гбайта.
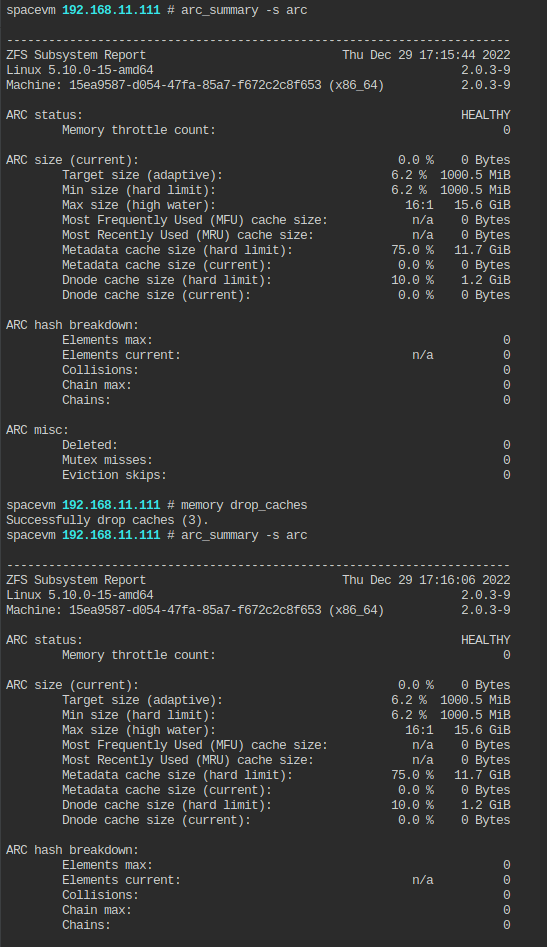
Минимальный размер ARC для более комфортной работы ФС без активного режима записи/перезаписи в файлы ВМ (например, этим грешат базы данных), примерно равен 1 Гбайт на хост + 1 Гбайт на 1 Тбайт, но фактически при кэше меньше 3 Гбайт могут возникнуть проблемы с "отвалом" хранилища, и для работы с активной перезаписью лучше использовать формулу 1 Гбайт + 4-5 Гбайт на 1 Тбайт без дедупликации, 5-6 Гбайт - с дедупликацией. Разово задать максимальный размер кэша до перезагрузки можно командой:
echo $[ N*1048576*1024 ] > /sys/module/zfs/parameters/zfs_arc_max
Параметр zfs_arc_max не может быть ниже текущего минимального размера кэша (zfs_arc_min), который можно посмотреть в выводе команды arc_summary в строке Min size (hard limit). Чтобы указать zfs_arc_max ниже данного значения, необходимо сперва таким же образом задать параметр zfs_arc_min. Важно помнить, что эти параметры не могут быть менее 64 Мбайт, а также больше объёма ОЗУ на узле. В противном случае эаданные значения параметров будут проигнорированы.
Пример временного изменения максимального размера кэша до перезагрузки (видно изменение Max size (high water)):
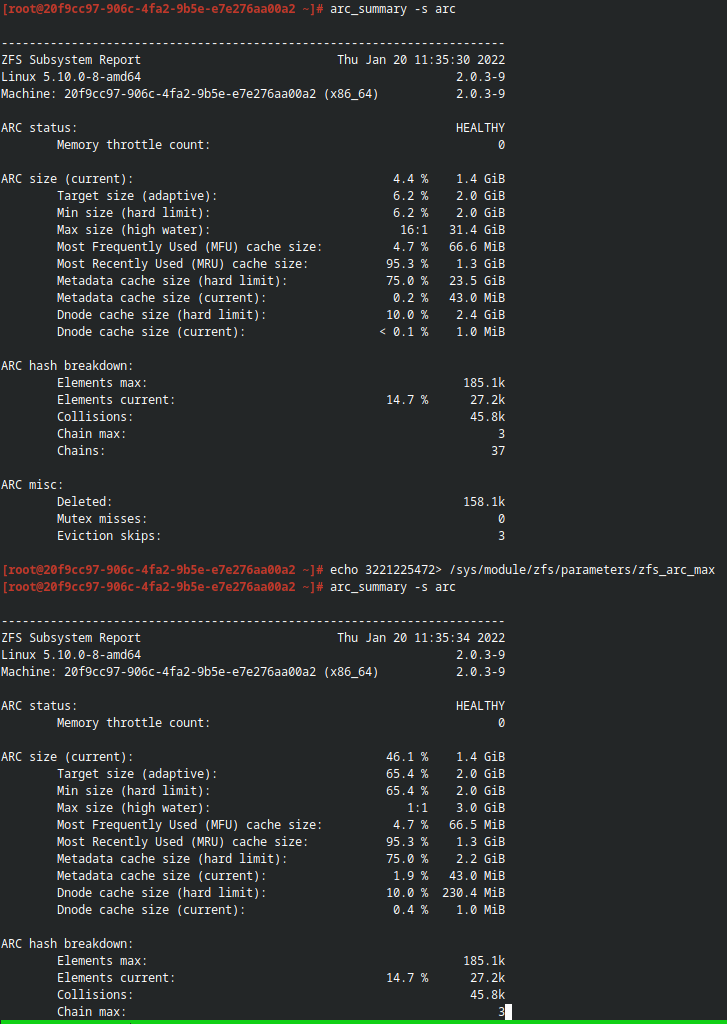
3гб: 3221225472
6гб: 6442450944
10гб: 10737418240
15гб: 16106127360
echo options zfs zfs_arc_max=16106127360>> /etc/modprobe.d/zfs.conf
update-initramfs -u
-
l2arc - на чтение - он собирает используемые в данный момент обращения и передает их через себя, что ускоряет запросы чтения к файловой системе хранилища. Минимальный размер l2arc примерно рассчитывается по формуле 2000 байт ARC на 1 блок l2arc, размер которого зависит от ashift ZFS-пула. Т.е. чем больше ashift, тем больше должен быть l2arc, но "раздувать" его за пределы 500 байт на 1 блок данных пула смысла нет - нельзя отдавать весь ARC под нужды l2arc, т.к. при максимальной загрузке вместо оперативной памяти вы будете работать с вашим устройством кэширования.
-
zil (slog) - кэширование записи. Каждая операция записи на пул будет считаться совершённой при попадании в zil, а на устройства хранения будет попадать уже т.н."дельта" всех операций с минимальным количеством "грязных данных". Минимальный размер zil устройства рассчитывается примерно из скорости работы вашего устройства, где будет размещён лог, и времени задержки записи "грязных данных" * 2. Максимальный размер для конкретной системы нужно определять индивидуально, но на практике размер больше, чем скорость устройства * 10 с, имеет смысл только в узкоспециализированных, направленных на постоянное краткосрочное изменение данных с минимальной задержкой.
Пример размеров разделов кэширования и логов:
zil
приблизительная скорость записи на устройство:
[root@04bdd07c-5b93-40b3-9b52-148993161241 ~]#`sync; dd if=/dev/urandom of=tempfile bs=1M count=1024; sync`
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 6.10459 s, 176 MB/s
[root@04bdd07c-5b93-40b3-9b52-148993161241 ~]#`sync; dd if=/dev/urandom of=tempfile bs=1M count=1024; sync`
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 6.31901 s, 170 MB/s
[root@04bdd07c-5b93-40b3-9b52-148993161241 ~]#`sync; dd if=/dev/urandom of=tempfile bs=1M count=1024; sync`
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 7.0737 s, 152 MB/s
[root@04bdd07c-5b93-40b3-9b52-148993161241 ~]#`sync; dd if=/dev/urandom of=tempfile bs=1M count=1024; sync`
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 5.9285 s, 181 MB/s
Примерно 170 Mбайт/с, следовательно, раздел свыше 1700 Мбайт (1.7 Гбайт) будет по сути бесполезным для данной системы. Округляем до 2 Гбайт для ровного счёта и получаем необходимый размер раздела под zil. Если переопределить время сброса данных на диск, то можно раздувать этот раздел больше, но фактического смысла в этом нет.
С l2arc нужно посчитать немного больше:
например, размер zfs_arc_max определён в 10 Гбайт.
Смотрим ashift раздела:
zpool get all "ваш_пул_zfs" | grep ashift`
"ваш_пул_zfs" ashift 13 local
ashift это размер логического блока ZFS, равный степени двойки. T.е. ashift13=2^13=8192 байт - размер сектора ZFS.
Оставляем ¾ ARC свободной при максимальной загрузке (можно использовать без особых потерь до ⅔ ARC, но для
невысоконагруженных на чтение систем ¼ более чем достаточно), помня что в ARC 1 блок занимает примерно 400 байт,
берём 512 для упрощения чисел и рассчитываем размер, при котором l2arc максимально занял бы примерно ¼ основного кэша):
10737418240/4=2684354560/512=5242880 - количество возможных блоков в l2arc.
Далее 5242880*8192=42949672960/1024=41943040/1024=40960/1024=40 Гбайт.
Итого при ashift13 и 10 Гбайт ARC размер l2arc может варьироваться от 40 до 100 Гбайт.
Больший размер или не даст улучшения скорости работы хранилища, или будет даже уменьшать её.
Импорт ZFS-пулов
- Получение имен и параметров импортируемых ZFS-пулов
zpool import
- Импорт в систему ZFS-пулов
zpool import -C <pool_name> -- импорт из файла кэша, если пул там прописан
zpool import -d /dev/disk/by-id <pool_name> -- при проблемах с файлом кэша или если запись о ZFS-пуле из кэша пропала (например, если ZFS-пул не импортировался ввиду отсутствия дисков на этапе загрузки, а потом с исправными пулами проводились какие-либо манипуляции, не импортированные ZFS-пулы "забываются" кэшем).
Внимание
Важно указать каталог /dev/disk/by-id, так как в противном случае возможен импорт ZFS-пула с "короткими" именами устройств, например, /dev/sdc. Это может привести при последующей перезагрузке к пропаданию устройства из ZFS-пула, так как такие короткие имена назначаются устройствам лишь на основе порядка их определения, что может меняться от загрузки к загрузке, и одно и то же устройство может получать различные короткие имена.
- Проверка появления в системе
zpool list
- Чтобы он сохранился после перезагрузки, нужно пересоздать кэш с указанием этого ZFS-пула.
zpool set cachefile=/etc/zfs/zpool.cache <pool_name>
Загрузка системы с неполным набором устройств (дисков, LUN), входящих в ZFS-пулы
Если ZFS-пул, в котором недостаёт устройств, обладает достаточной избыточностью, чтобы компенсировать их отсутствие (для типа mirror должно остаться хотя бы одно устройство, для типа raidz1 возможно остаться без одного, для raidz2 -- без двух устройств, устройства горячего резерва и кэша чтения на работоспособность не влияют), то такой ZFS-пул импортируется при старте системы обычным образом. В противном случае этот ZFS-пул не импортируется. Если есть техническая возможность вернуть в систему недостающие устройства под теми же именами, то после их возврата пострадавший ZFS-пул будет импортирован автоматически при перезагрузке узла, либо "на лету" через CLI -- после проверки возможности импорта ZFS-пула командой zpool import или zpool import -d /dev/disk/by-id, см. пункт выше "Импорт в систему ZFS-пулов". Для проверки состояния кэша используют команду CLI zdb. Она отображает запомненные в кэше ZFS-пулы, входящие в них устройства, их типы, а также некоторую дополнительную информацию.
Внимание
Чтобы ZFS-пул был автоматически импортирован при старте системы, он должен быть прописан в кэше /etc/zfs/zpool.cache. Записи о ZFS-пулах там появляются при их создании, также они модифицируются при манипуляциях с ZFS-пулами. Если какой-то ZFS-пул не импортирован из-за повреждений, т.е. не виден в системе, то в момент модификации кэша (изменений имеющихся или создания новых ZFS-пулов) записи о нём УДАЛЯЮТСЯ из кэша, и при следующей перезагрузке данный ZFS-пул не будет импортирован автоматически. Это необходимо учитывать, и если есть необходимость и возможность вернуть данный ZFS-пул в работу, и в то же время проводить какие-то действия над имеющимися ZFS-пулами узла, то нужно обеспечить работоспособность повреждённого ZFS-пула и импортировать его вручную до перезагрузки системы, либо импортировать его вручную после перезагрузки. Первый вариант предпочтительней, особенно если ZFS-пул участвует, например, в кластерном хранилище.
Также может быть полезна информация из меток устройств, входивших в ZFS-пул -- zdb -l <device>. Будет показано, принадлежит ли устройство ZFS-пулу, какому именно, какой GUID у этого устройства и на каком хосте создан данный ZFS-пул.
Пример:
Информация из кэша о некотором ZFS-пуле:
Команда zdb
# zdb
zfs_115:
version: 5000
name: 'zfs_115'
state: 0
txg: 4
pool_guid: 879109887279304795
errata: 0
hostid: 4212788997
hostname: 'f96b4837-a7e3-43a1-ab52-37bdc4677b82'
com.delphix:has_per_vdev_zaps
vdev_children: 1
vdev_tree:
type: 'root'
id: 0
guid: 879109887279304795
create_txg: 4
children[0]:
type: 'disk'
id: 0
guid: 15989658986416599112
path: '/dev/disk/by-id/scsi-SATA_ST1000NX0313_S470HK28-part1'
devid: 'ata-ST1000NX0313_S470HK28-part1'
phys_path: 'pci-0000:00:1f.2-ata-1.0'
whole_disk: 1
metaslab_array: 256
metaslab_shift: 33
ashift: 13
asize: 1000189984768
is_log: 0
create_txg: 4
com.delphix:vdev_zap_leaf: 129
com.delphix:vdev_zap_top: 130
features_for_read:
com.delphix:hole_birth
com.delphix:embedded_data
Здесь мы видим, что ZFS-пул имеет имя name: 'zfs_115', GUID pool_guid: 879109887279304795, содержит одно устройство /dev/disk/by-id/scsi-SATA_ST1000NX0313_S470HK28-part1 с GUID в пределах ZFS-пула guid: 15989658986416599112. Пул принадлежит хосту hostname: 'f96b4837-a7e3-43a1-ab52-37bdc4677b82'.
Просмотрим информацию из метки этого устройства:
zdb -l /dev/disk/by-id/scsi-SATA_ST1000NX0313_S470HK28-part1
------------------------------------
LABEL 0
------------------------------------
version: 5000
name: 'zfs_115'
state: 0
txg: 2321441
pool_guid: 879109887279304795
errata: 0
hostid: 4212788997
hostname: 'f96b4837-a7e3-43a1-ab52-37bdc4677b82'
top_guid: 15989658986416599112
guid: 15989658986416599112
vdev_children: 1
vdev_tree:
type: 'disk'
id: 0
guid: 15989658986416599112
path: '/dev/disk/by-id/scsi-SATA_ST1000NX0313_S470HK28-part1'
devid: 'ata-ST1000NX0313_S470HK28-part1'
phys_path: 'pci-0000:00:1f.2-ata-1.0'
whole_disk: 1
metaslab_array: 256
metaslab_shift: 33
ashift: 13
asize: 1000189984768
is_log: 0
DTL: 50892
create_txg: 4
features_for_read:
com.delphix:hole_birth
com.delphix:embedded_data
labels = 0 1 2 3
Видим, что устройство принадлежит ZFS-пулу с именем name: 'zfs_115', GUID пула pool_guid: 879109887279304795, а само устройство имеет GUID в ZFS-пуле guid: 15989658986416599112. Имя хоста hostname: 'f96b4837-a7e3-43a1-ab52-37bdc4677b82'.