Кластерные транспорты
Кластерные транспорты
Кластерные транспорты — это общее название для кластерных (GFS2) и распределённых (Gluster) транспортов. Фактически транспорт - это набор сервисов на всех серверах кластера, имеющих сетевую связность друг с другом, поддерживающих постоянное общение друг с другом и кворум для реализации блокировок на файловые системы. Для GFS2 это связка сервисов watchdog, corosync, dlm, sbd. Для Gluster это связка сервисов glusterd и порождаемых им.
В одном транспорте можно использовать несколько однотипных файловых систем, например, у одного транспорта Gluster можно создать несколько томов и пулов данных на последних, у одного транспорта GFS2 можно использовать несколько LUN и пулов данных на последних. Именно поэтому логично выделить кластерный транспорт в отдельную сущность (например, VMFS у Vmware, - это тоже одновременно кластерный транспорт и файловая система).
Создание
Для создания кластерного транспорта необходимо перейти в раздел Хранилища - Кластерные хранилища - Кластерные транспорты основного меню и нажать кнопку Создать. В открывшемся окне необходимо заполнить следующие поля:
-
название (если не указано, то автоматически сгенерируется уникальное имя);
-
описание;
-
кластер, на узлах которого будет разворачиваться кворум (выбор из раскрывающегося списка);
-
тип транспорта (выбор из раскрывающегося списка);
-
внешняя сеть (либо множество внешних сетей для GFS2), физическая сеть которой будет использована для обмена данными между участниками кворума (выбор из раскрывающегося списка);
После внесения изменений необходимо подтвердить операцию, нажав кнопку ОК.
HOWTO создать общий(е) для кластера пул(ы) данных GFS2 на LUN(s)
-
Создать сетевое блочное iscsi или fc хранилище. Проверить, что оно доступно на всех узлах кластера. Проверить, что его LUN(s) видны на всех узлах кластера. Подробности смотрите в блочных хранилищах.
-
Создать внешнюю сеть (необязательный, но рекомендуемый шаг, см. примечание о сетевой конфигурации ниже).
-
Создать кластерный транспорт gfs2. Для удобства можно выбрать LUN, который будет сразу отформатирован (если он не содержит файловую систему GFS2, иначе его служебная информация модифицируется для работы с текущим кластером, а данные остаются нетронутыми), примонтирован, и на нём будет создан пул данных. В дальнейшем можно отформатировать, примонтировать и создать пул данных на других LUN. При выборе нескольких внешних сетей их приоритет (см. примечание о сетевой конфигурации) убывает по порядку сетей в списке. Сеть mgmt добавляется всегда, но с наименьшим приоритетом. Пример 1: при создании транспорта не указано ни одной внешней сети. Результат: используется только одна сеть mgmt. Пример 2: при создании транспорта указаны внешние сети ext1, ext0 (в таком порядке). Результат: максимальный приоритет
у ext1, далее ext0, наименьший приоритет у сети mgmt.
HOWTO создать общий(е) для кластера пул(ы) данных GFS2 на LUN(s), если уже есть кластерный транспорт gfs2
-
Отформатировать LUN в файловую систему GFS2. Если LUN уже содержит ФС GFS2, созданную ранее в другом кластере, см. примечание ниже "Смена имени таблицы блокировок при монтировании LUN, где ранее уже был развернут GFS2 в другом кластере"
-
Примонтировать LUN (он должен примонтироваться на всех узлах кластера с транспортом).
-
Создать пул данных GFS2 на этом LUN или отсканировать, если ФС с дата-пулом существовала ранее.
Информация о сетевой конфигурации GFS2 и Gluster
Роль сети для кластерного транспорта GFS2 и Gluster различна. Так в случае Gluster одна и та же сеть используется и для служебной информации, и для обмена данными между разделами (brick) тома, т.е. трафик по выбранной сети будет достаточно велик при операциях записи на Gluster том или таких операциях, как замена раздела или ребалансировка. Для кластерного транспорта GFS2 сеть необходима для работы служб corosync и dlm, то есть для контроля целостности кластерного транспорта (не путать с кластером SpaceVM) и данных о блокировках. Поэтому для GFS2 трафик существенно меньше, но как для Gluster, так и для GFS2 критично важны и сетевая связность, и минимальные сетевые задержки. Gluster позволяет использовать только какую-нибудь одну сеть (mgmt или внешнюю). Для отказоустойчивости желательно обеспечить избыточность в выбранной сети средствами агрегации. GFS2, напротив, позволяет использовать до 8 сетей для работы кластерного транспорта с заданием приоритета (только одна сеть используется в данный момент, а в случае её отказа выбирается следующая по приоритету, и т.д.). В любом случае рекомендуется разделять трафик кластерных транспортов, трафик управления и СХД трафик в случае iSCSI сетей.
Описание работы GFS2 транспорта
Работа GFS2 транспорта обеспечивается службами corosync, DLM, SBD, косвенно -- ntp.
Corosync обеспечивает отслеживание добавления и удаления узлов из кластера (в нашем случае для транспорта GFS2 ), определение наличия кворума (при отсутствии кворума обмен данными с хостом блокируется для предотвращения ситуации "split-brain"), надёжный и упорядоченный обмен сообщениями между узлами (т.н. протокол Totem). Большое значение для функционирования Totem имеет токен.
Токен -- это некий маркер, пакет данных, циркулирующий между узлами кластера Corosync. Его отсутствие на узле в течение некоторого времени служит основанием для пересоздания кластера службами Corosync на этом узле. Возможными причинами этого могут быть, к примеру, нестабильность сети, отказ узла, который принял токен последним. Перед принятием решения о пересоздании кластера предпринимается несколько попыток повторного отправления токена.
Кворум Corosync достигается при фактическом наличии в кластере узлов с общим числом голосов (N/2)+1, где N -- число голосов, вычисленное из заданной конфигурации кластера. Узлам типа Node назначается один голос, узлам типа Controller+Node -- два. Например, имеется кластер из трёх узлов, один из которых Controller+Node, а два других Node, всего голосов (Votes) 2+1+1 = 4, здесь кворум достигается при числе голосов не менее 3. Следовательно, работоспособность кластера сохранится при потере любого одного из Node, а при любом другом сочетании отказов (Controller, оба узла Node сразу) кластер будет остановлен.
На данный момент кластер SpaceVM и кластер Corosync функционируют параллельно после того, как путём создания или реконфигурации кластерного транспорта GFS2 создаётся конфигурация Corosync с узлами, входящими в кластер SpaceVM.
Сети, которые использует Corosync -- это сети, которые заданы при создании/реконфигурации кластерного транспорта. С версии SpaceVM 6.3.1 можно задавать более одной сети для этих целей, а также менять конфигурацию сетей кластерного транспорта без его остановки.
Служба DLM управляет распределёнными блокировками при операциях с примонтированными GFS2 файловыми системами. Эта служба связана со службой SBD, которая отвечает за ограждение узлов. SpaceVM монтирует GFS2 LUN в режиме управляемой dlm блокировки (lock_dlm), при этом создаётся отдельное пространство блокировок (lockspace) для каждой примонтированной ФС GFS2. От состояния этих пространств блокировок на данном узле зависит доступность данных на соответствующих LUN.
Ограждение узлов в кластере GFS необходимо при угрозе, например, параллельного доступа узлов, не имеющих между собой связи, к одному и тому же ресурсу (например, GFS2 файловой системе). Это возможно при потере связи с узлом, вследствие чего остальной кластер не будет иметь информации о занимаемых данным узлом общих ресурсах (для GFS2 это группы блоков на диске с ФС). При определении такой ситуации узлы, потерявшие кворум, могут быть ограждены самостоятельно посредством сторожевого таймера (watchdog, WDT), который находится в распоряжении службы SBD. Именно поэтому при ограждении узла в логах BMC (iDRAC, iLO, IPMI и т.д.) можно увидеть сообщения о сработавшем WDT.
При определении отказа узла на уровне кластера SpaceVM (ВД) срабатывает выбранный в Web-интерфейсе SpaceVM механизм ограждения, в т.ч. при помощи IPMI-команд.
При ограждении узла прочие узлы отменяют незавершённые изменения, относящиеся к ограждённому, при помощи отката журналов GFS2. Этим обеспечивается целостность данных на ФС. Потеря данных в кэше ВМ, располагавшихся на ограждённом хосте, считается меньшей проблемой по сравнению с непредсказуемым состоянием кластерного хранилища и потери данных на нём.
Служба NTP обеспечивает синхронность времени на узлах, что критично для вхождения узлов в кластер Corosync.
Note
При старте узла службы DLM, Corosync, SBD остановлены до тех пор, пока не будет достигнуто состояние синхронности
времени с контроллером, либо если это сам контроллер -- с внешним NTP-сервером. При отсутствии такового в настройках
ожидается синхронность с локальными часами, что занимает довольно много времени. До этого момента кластерный транспорт
на соответствующих узлах не запущен, в Web-интерфейсе его состояние отображается как FAILED. При достижении
синхронности ситуация приходит в норму. Состояние NTP на узлах можно увидеть командой в CLI контроллера node nodes-cli "ntp check".
Watchdog
При наличии аппаратного таймера watchdog сервер будет следить за своим состоянием через него.
При отсутствии такового при включении сервера будет активирован программный watchdog (softdog).
Просмотр и управление watchdog происходит в CLI командами system watchdog *.
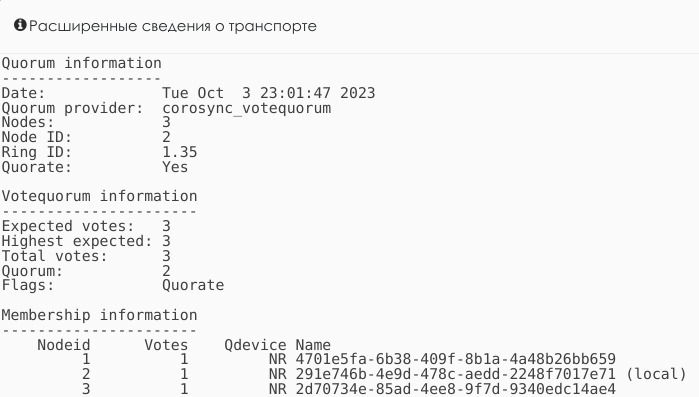
Пример расширенных сведений кластерного транспорта GFS2. Здесь показан статус кворума corosync. Видно, что в транспорте
3 узла (Nodes: 3), данный узел имеет ID 2 (Node ID 2), всего 3 голоса (Expected votes: 3 ). Для кворума необходимо 2
(Quorum: 2), кворум достигнут (Flags: Quorate):
Пример команды storage gfs2 в CLI кластерного транспорта GFS2.
Пример команды вывода конфигурации corosync storage corosync_conf в CLI. Кластерный транспорт состоит из 3 узлов,
узел 1 (nodeid=1) имеет 2 голоса (quorum_votes=2), т.к. является, очевидно, Controller+Node, остальные 2 узла (nodeid=2 и nodeid=3) имеют по одному голосу (quorum_votes=1). Транспорт сконфигурирован
с 2 сетями: сеть mgmt (ring0, linknumber 0) и одна внешняя сеть (ring1, linknumber 1). При этом более высокий приоритет
(knet_link_priority = 2) у внешней сети, то есть она используется по умолчанию.
Имя кластера (cluster_name) - это первые 8 символов UUID кластера, а версия конфигурации (config_version) зависит от времени создания
кластерного транспорта.
logging {
to_logfile: yes
logfile: /var/log/corosync/corosync.log
timestamp: on
}
nodelist {
node {
name: 6cca2ca9-a1ce-47a0-83cd-b501a780955d
nodeid: 1
quorum_votes: 2
ring0_addr: 6cca2ca9-a1ce-47a0-83cd-b501a780955d
ring1_addr: 6cca2ca9-a1ce-47a0-83cd-b501a780955d-ex1-120
}
node {
name: 6137ca41-6964-4791-b000-98fc84ee0fe3
nodeid: 2
quorum_votes: 1
ring0_addr: 6137ca41-6964-4791-b000-98fc84ee0fe3
ring1_addr: 6137ca41-6964-4791-b000-98fc84ee0fe3-ex1-121
}
node {
name: e0ec5e71-2f76-4178-aad4-4951b2979b9b
nodeid: 3
quorum_votes: 1
ring0_addr: e0ec5e71-2f76-4178-aad4-4951b2979b9b
ring1_addr: e0ec5e71-2f76-4178-aad4-4951b2979b9b-ex1-122
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: 7157ad2f
config_version: 1778594812838566
ip_version: ipv4
secauth: off
version: 2
keyfile: /var/lib/ecp-veil/controller/local_data/authkey
transport: knet
token: 3000
join: 60
threads: 2
max_messages: 20
vsftype: none
window_size: 170
token_retransmits_before_loss_const: 10
interface {
linknumber: 0
knet_transport: sctp
knet_link_priority: 1
}
interface {
linknumber: 1
knet_transport: sctp
knet_link_priority: 2
}
}
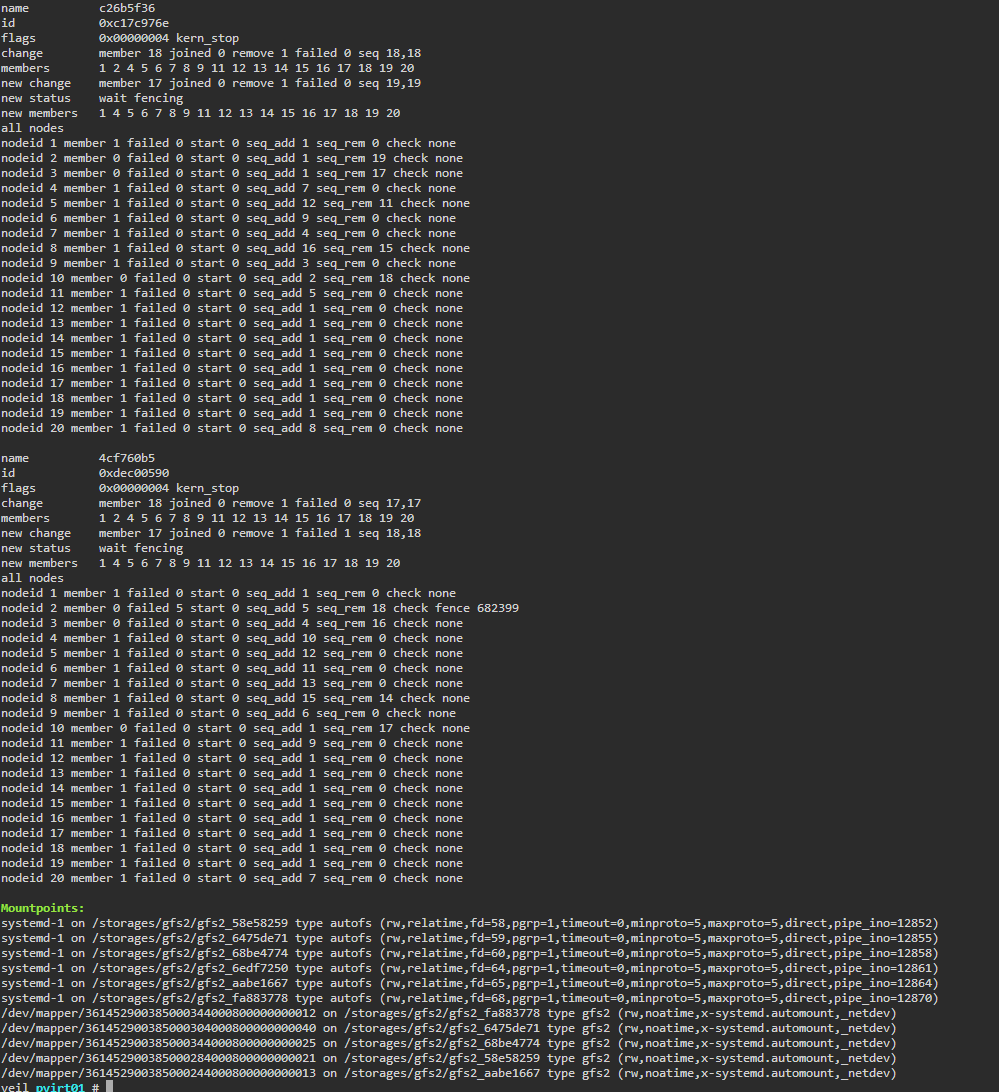
Пример правильной работы двух пространств блокировок (dlm lockspaces) в выводе команды CLI storage gfs2:
lm Lockspaces info:
dlm lockspaces
name a34be778
id 0x66978c01
flags 0x00000000
change member 3 joined 1 remove 0 failed 0 seq 3,3
members 1 2 3
all nodes
nodeid 1 member 1 failed 0 start 1 seq_add 3 seq_rem 0 check none
nodeid 2 member 1 failed 0 start 1 seq_add 1 seq_rem 0 check none
nodeid 3 member 1 failed 0 start 1 seq_add 2 seq_rem 0 check none
name b846a358
id 0xec09038a
flags 0x00000000
change member 3 joined 1 remove 0 failed 0 seq 3,3
members 1 2 3
all nodes
nodeid 1 member 1 failed 0 start 1 seq_add 1 seq_rem 0 check none
nodeid 2 member 1 failed 0 start 1 seq_add 1 seq_rem 0 check none
nodeid 3 member 1 failed 0 start 1 seq_add 3 seq_rem 2 check none
gfs2_lockcapture info:
List of all the mounted GFS2 filesystems that can have their lockdump data captured:
a20a1521:291e746b-4e9d-478c-aedd-2248f7017e71(id:2)
a20a1521:a34be778 --> /dev/mapper/36000d31004a4f4000000000000000140 on /storages/gfs2/gfs2_df0a4266 type gfs2 (rw,noatime,nodiratime,debug,x-systemd.automount,_netdev) [a20a1521:a34be778]
a20a1521:b846a358 --> /dev/mapper/3600143801259dcf30001100000200000 on /storages/gfs2/gfs2_b846a358 type gfs2 (rw,noatime,nodiratime,debug,x-systemd.automount,_netdev) [a20a1521:b846a358]
Mountpoints:
systemd-1 on /storages/gfs2/gfs2_b846a358 type autofs (rw,relatime,fd=63,pgrp=1,timeout=0,minproto=5,maxproto=5,direct,pipe_ino=47126)
/dev/mapper/3600143801259dcf30001100000200000 on /storages/gfs2/gfs2_b846a358 type gfs2 (rw,noatime,nodiratime,debug,x-systemd.automount,_netdev)
/dev/mapper/36000d31004a4f4000000000000000140 on /storages/gfs2/gfs2_df0a4266 type gfs2 (rw,noatime,nodiratime,debug,x-systemd.automount,_netdev)
gfs2 lun /dev/mapper/3600143801259dcf30001100000200000 journals info:
3/3 [fc7745eb] 1/20 (0x1/0x14) +0: File journal0
4/4 [8b70757d] 2/32859 (0x2/0x805b) +0: File journal1
5/5 [127924c7] 3/65698 (0x3/0x100a2) +0: File journal2
6/6 [657e1451] 4/98537 (0x4/0x180e9) +0: File journal3
7/7 [fb1a81f2] 5/131376 (0x5/0x20130) +0: File journal4
8/8 [8c1db164] 6/164215 (0x6/0x28177) +0: File journal5
9/9 [1514e0de] 7/197054 (0x7/0x301be) +0: File journal6
10/10 [6213d048] 8/229893 (0x8/0x38205) +0: File journal7
gfs2 lun /dev/mapper/36000d31004a4f4000000000000000140 journals info:
3/3 [fc7745eb] 1/131 (0x1/0x83) +0: File journal0
4/4 [8b70757d] 2/33155 (0x2/0x8183) +0: File journal1
5/5 [127924c7] 3/66179 (0x3/0x10283) +0: File journal2
6/6 [657e1451] 4/99203 (0x4/0x18383) +0: File journal3
storage gfs2 FS WITHDRAWN; FSCK NEEDED). Если такое есть хотя бы на каком-то узле, следует отмонтировать ФС
на всех узлах и провести проверку файловой системы.
Соответствие имени LUN имени пространства блокировок можно увидеть в выводе в секции gfs2_lockcapture info.
Пример команды storage dlm-conf в CLI :

Пример команды storage gfs2 в CLI (здесь видно, что кворум ожидает завершения ограждения узла,
рекомендуется проверить, почему узел не ограждается и при необходимости попытаться завершить
ограждение командой dlm_tool fence_ack {nodeid}):
Gluster транспорт
Минимальное количество узлов
В кластере для создания транспорта должно быть не менее 2 узлов. При создании транспорта типа Gluster на 2 узлах надо понимать, что такая конфигурация может создать ситуацию, когда узлы не могут определить мастера при потере сетевой связности (split-brain), а значит - могут писать различающиеся данные в одно место. При создании транспорта типа GFS2 на 2 узлах такая конфигурация может повлечь за собой возможность ограждения 2 узлов.
Выбор внешней сети
Рекомендуется использовать отдельную от сети управления внешнюю сеть!
После создания транспорта без использования внешней сети убедитесь с помощью кнопки
Получение расширенных сведений о транспорте,
что связь узлов идёт через UUID узлов, а с использованием внешней сети через
UUID узлов плюс имя внутреннего интерфейса. С помощью команды hosts на любом узле можно
удостовериться, что UUID узла плюс имя внутреннего интерфейса соответствует IPv4-адресу интерфейса.
Устройство томов Gluster и действия с ними описаны в пункте Gluster тома.
Добавление узлов к существующему кластерному транспорту Gluster:
- Введите узлы в кластер Space.
- При функционировании существующего кластерного транспорта через внешнюю сеть подключите узлы к этой внешней сети.
- В окне существующего кластерного транспорта нажмите кнопку Переконфигурирование. При этом вновь добавленные к кластеру узлы будут присоединены к существующему кластерному транспорту.
- При наличии пулов данных типа Gluster в меню Хранилища - Пулы данных на вновь подключённых узлах нажмите Сканировать. Пулы данных станут доступны на этих узлах.
Удаление узлов из кластерного транспорта Gluster (например, перед выводом из кластера)
- Остановите или выключите ВМ, чьи диски находятся на томах Gluster в данном кластерном транспорте. На время удаления не проводите операций загрузки файлов на пулы данных типа Gluster в данном кластере.
- Удалите или замените разделы томов Gluster, находящиеся на узлах, которые подлежат удалению.
- Отмонтируйте тома Gluster от соответствующих узлов.
- В меню кластерного транспорта нажмите кнопки отключения нужных узлов от транспорта.
Замена узла с имеющимся кластерным транспортом
Окно состояния транспорта
Для получения информации о транспорте необходимо нажать на его название. В окне состояния транспорта отображаются сведения о нем, разделенные на группы:
-
информация;
-
события;
-
теги.
Управление работой транспорта происходит в окне состояния, где доступны следующие операции:
-
удаление;
-
переконфигурирование (добавление новых серверов кластера);
-
получение расширенных сведений о транспорте.
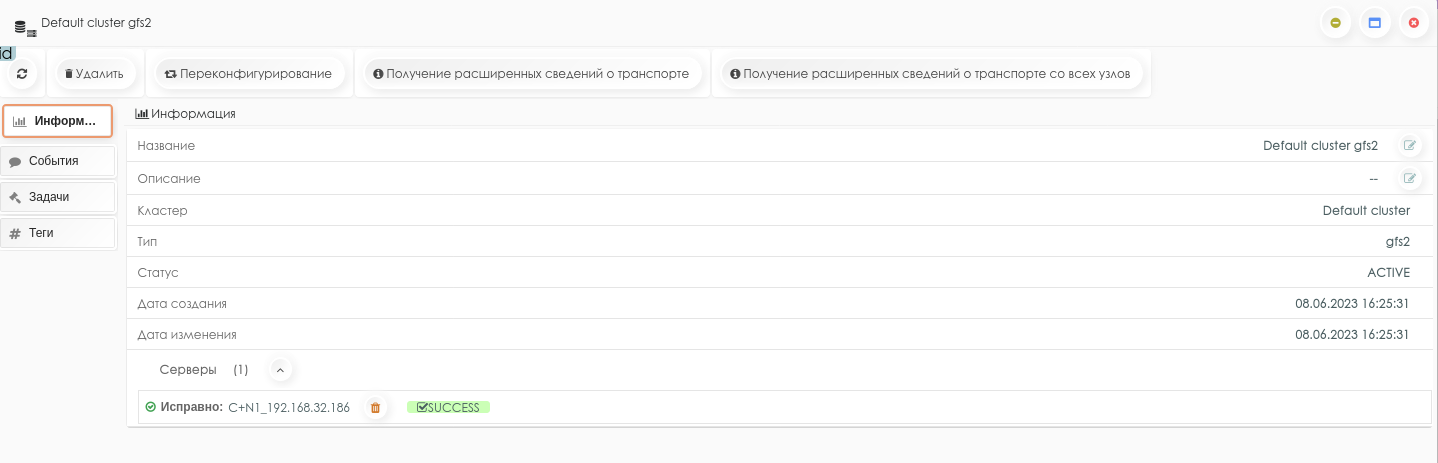
Вкладка Информация содержит следующие сведения о транспорте:
-
название (редактируемый параметр);
-
описание (редактируемый параметр);
-
кластер;
-
тип;
-
статус;
-
даты создания;
-
дата обновления;
-
серверы со статусами (раскрывающийся список).
Пример информации кластерного транспорта gfs2:
События
Вкладка События содержит сообщения о работе транспорта с возможностью их сортировки по признакам - «По всем типам», «Ошибки», «Предупреждения», «Информационные».
Теги
Вкладка Теги содержит список присвоенных транспорту меток. Также имеется возможность обновления, создания и применения тега.
Watchdog
Для работы кластерных транспортов OCFS и GFS2 требуется наличие устройства /dev/watchdog. Появление этого устройства в системе зависит от того, загружен ли правильный (один из множества вариантов) модуль ядра для разных возможных плат bmc. SpaceVM автоматически при загрузке, раз в сутки или по требованию администратора, проверяет наличие устройства, и при его отсутствии пытается последовательно загрузить модули ipmi-watchdog, iTCO_wdt, softdog. После каждой попытки проверяется наличие устройства, если оно есть, дальше попытки не ведутся. Указанный выше порядок, с нашей точки зрения, является наиболее универсальным для тех серверов, которые подвергались тестированию. При необходимости стоит выбирать подходящий для своего сервера модуль.
Управлять watchdog можно в CLI командами system watchdog *.
Добавление/Удаление узлов от кластерного транспорта GFS2
- Если узел, который нужно удалить, активен, то необходимо перевести его в сервисный режим.
- Нажать кнопку Реконфигурировать у кластерного транспорта.
Что произойдет:
- Возьмутся все активные узлы кластера.
- На всех активных узлах пропишется новая конфигурация corosync и dlm.
- На всех активных узлах сервисы corosync перепрочитают конфигурацию.
Смена имени таблицы блокировок при монтировании LUN, где ранее уже был развернут GFS2 в другом кластере
Следует зайти в CLI любого сервера в составе кластера с GFS2 и выполнить команду
tunegfs2 -L {cluster_id}:{lun_id} {lun_device}.
Пример смены имени таблицы блокировок
tunegfs2 -L 22c7867a:5aa6f80f /dev/mapper/3600143801259dcf30000b00000220000
Переменные:
-
cluster_id - первые 8 символов id кластера (если id кластера 22c7867a-f705-46f1-a01d-d215f4f6b388, то нам нужны 22c7867a)
-
lun_id - первые 8 символов id LUN (если id LUN 5aa6f80f-4c8c-4c84-8037-c29800b93f92, то нам нужны 5aa6f80f)
-
lun_device - путь LUN, например /dev/mapper/3600143801259dcf30000b00000220000
id сущности
Его можно посмотреть и скопировать в буфер кнопкой Копировать в левом верхнем углу окна сущности.
После этого можно снова попробовать примонтировать LUN к серверам кластера.
Журналы файловой системы GFS2 и их добавление
При формативании LUN в файловую систему GFS2 необходимо выбрать опцию Максимальное количество узлов в кластере (по умолчанию 16, максимум 64). Это необходимо для создания на LUN отдельных файлов журналов (по умолчанию размер 32 Mбайт) на каждый узел в составе кластера. Если необходимо превысить текущее количество узлов, использующих этот LUN, то надо соответственно увеличить количество журналов.
-
Посмотреть текущие журналы и их количество можно в CLI любого сервера в составе кластера с GFS2, выполнив команду:
storage gfs2. -
Добавить журналы можно в CLI любого сервера (предварительно обязательно смонтировав на узле этот LUN) в составе кластера с gfs2 , выполнив команду:
gfs2_jadd -j {journal_count} {lun path}.Пример команды
gfs2_jadd -j 2 /dev/mapper/3600143801259dcf30000b00000220000
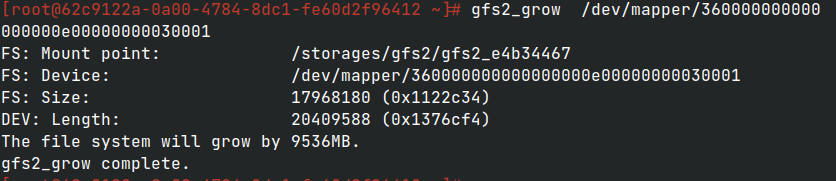
Расширение файловой системы GFS2
Перезагрузка узлов
Перед выполнением расширения GFS2 следует прочитать и задействовать Действия после изменения размера LUN и перезагрузиться.
Пример расширения GFS2:
Действия при отключении питания блочного хранилища со всех узлов во время работы GFS2
Аварийный режим
Отключение хранилища во время работы GFS2 считается аварийным режимом и никогда не рекомендуется. Менеджеры кластерных блокировок dlm не знают точно, что на файловой системе происходит после коллективного отключения, поэтому и требуют проверки.
Действия:
- Отмонтировать LUN на всех узлах через Web-интерфейс. При ошибках отмонтирования можно просто зайти в CLI сервера и удалить записи монтирования этого LUN из /etc/fstab. Главная цель - чтобы после перезагрузки LUN был отмонтирован на узле для дальнейшей работы команды fsck.
- Перезагрузить все узлы. При наличии других общих пулов данных можно перезагружать поочерёдно, выполнив перед этим перенос ВМ на другие узлы.
- Зайти на любой один узел и сделать
fsck.gfs2 -y {lun path}, напримерfsck.gfs2 -y /dev/mapper/3600143801259dcf30000b00000220000. Надо учитывать, что данная операция занимает продолжительное время и зависит от размера LUN. Например, для LUN размером 157 Тбайт fsck заняло 2 недели. - Примонтировать LUN на всех узлах. Рекомендуется монтировать поочерёдно по одному узлу.
- Проверить, что пул данных стал активен на всех узлах. Рекомендуется создать и удалить виртуальный диск для проверки.